
These questions and answers could be helpful for both interviewers and interviewees. Sometimes database professionals, when asked to do an interview, become embarrassed as in most of cases they have no list of questions on hand and generating questions on the spot to cover all the topics is a bit difficult. So, interviewers can use this list to choose questions for an interview. For professional candidates these questions are a good way of updating their knowledge and keeping it in good shape. Beginners will find here good prompts allowing them to find out what aspects to focus on when preparing for an interview.
MS SQL Server Common Interview Questions And Answers
1. What is the difference between instance and database?
Show/Hide Answer
Database is an organized collection of objects – schemas, tables, indexes, views, stored procedures and so on.
An instance (an instance of the database engine) is an operating system service which manages databases. Each instance manages system databases and one or more user databases. It handles applications’ requests to work with their databases.
2. List all constraints in MS SQL Server and describe each of them.
Show/Hide Answer
NOT NULL, CHECK, UNIQUE, PRIMARY KEY, FOREIGN KEY.
https://technet.microsoft.com/en-us/library/ms189862(v=sql.105).aspx
3. What is a DML? Give examples of DML statements.
Show/Hide Answer
DML-Data Manipulation Language is a vocabulary of statements which allows to work (query, add, modify, remove) with data in a database.
SELECT, INSERT, UPDATE, DELETE are examples of DML statements.
4. What is a DDL? Give examples of DDL statements.
Show/Hide Answer
DDL-Data Definition Language is a vocabulary of statements which allows to define data structures in database.
CREATE, ALTER, DROP, TRUNCATE TABLE are examples of DDL statements.
5. Which types of joins do you know? Describe each of them.
Show/Hide Answer
[Inner] join – displays only the rows that have a match in both joined tables.
TableA TableB The result of INNER JOIN
![]()


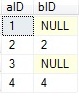
Left [outer] join – displays all rows from the first table in the JOIN clause.
For matched rows there will be corresponding rows from the
second table. Unmatched rows in the right (second) table do not appear (there
will be NULLs instead).
TableA TableB The result of LEFT JOIN
![]()
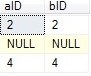
Right [outer] join – displays all rows from the second table in the JOIN clause.
For matched rows there will be corresponding rows from the
first table. Unmatched rows in the left(first) table do not appear(there
will be NULLs instead).
TableA TableB The result of RIGHT JOIN
![]()
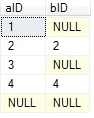
Full [outer] join – displays all rows in all joined tables are included, whether they are
matched or not. For rows which are matched to join criteria, there
will be corresponding row from other table. For rows which do not match
there will be NULLs instead.
TableA TableB The result of FULL JOIN
![]()
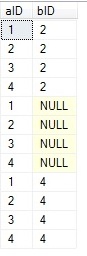
Cross join – displays each possible pairing of rows from the two tables in other words
displays each row from the first table combined with each row from the second table.
TableA TableB The result of FULL JOIN
![]()
6. What is a clustered table and what is a heap?
Show/Hide Answer
Clustered table is a table which has a clustered index. The data rows in these tables
are stored in an ordered way based on clustered index key values.
Heap is a table which does not clustered index. Data rows in these tables are stored
in an unordered structure.
7. What is the difference between clustered and nonclustered indexes?
Show/Hide Answer
When clustered index is created on table or view, the data rows is sorted and physically
stored based on index’s key values. So, heap becomes a clustered table. Only one clustered
index can be created for table (because data rows can be sorted in only one order).
Creating a nonclustered index does not change table’s data row order. It is a
separate structure which stores nonclustered index key values sorted by index’s
key values and a pointer to the data row that contains the key value. In addition,
when table is a clustered table, the pointer is clustered index key. In case of heap
the pointer is row’s physical identifier. More than one nonclustered indexes can be
created for table (in SQL Server 2016 maximum 999 nonclustered indexes per table).
https://msdn.microsoft.com/en-us/library/ms190457.aspx
8. What is a view?
Show/Hide Answer
View is a virtual table which is made by predefined query that retrieve data from one or more tables.
Like tables, views have columns and data rows, however unlike tables, views (if they are not indexed) do not physically exist as a stored set of data values in a database.
Using views we can narrow the necessary data for specific users to make it more simple and understandable. Views also can be useful for summarizing data from one or more tables and continuously using it without writing the query every time. In addition, using views we can enhance security by granting users access to data without granting access to base tables.
https://msdn.microsoft.com/en-us/library/ms190174.aspx
9. What is a schema? What advantages can we take of the functionality of schema?
Show/Hide Answer
A schema is a separate entity within the database, where database objects are created and contained. We can create a new schema by using CREATE SCHEMA statement. When creating a database object we should mention its schema name. If schema name is not mentioned, object is created within default schema. Schemas can be protected by appropriate permissions and in this way we regulate data access and prevent its objects from unwanted access. Also, we can use schemas to combine logically related entities which will facilitate database management process.
https://technet.microsoft.com/en-us/library/dd283095(v=sql.100).aspx
10. What is a transaction? Which transaction statements do you know?
Show/Hide Answer
A transaction is a series of operations which act as a single unit of work.
It means that all changes made by statements included in transaction are either
wholly committed and become a permanent part of the database or wholly rolled back
and all changes made within transaction are erased.
BEGIN TRANSACTION, COMMIT [TRANSACTION], ROLLBACK [TRANSACTION], SAVE TRANSACTION, etc are transaction statements.
11. What is a nested transaction?
Show/Hide Answer
Nested transaction is a transaction which starts inside the scope of an existing transaction.
https://technet.microsoft.com/en-us/library/ms189336(v=sql.105).aspx
12. What is a @@TRANCOUNT function? How BEGIN TRANSACTION, COMMIT and ROLLBACK statements affect the value of @@TRANCOUNT?
Show/Hide Answer
@@TRANCOUNT function returns the number of opened transactions on the current connection.
In other words @@TRANCOUNT function shows the current transaction’s nesting level.
Each BEGIN TRANSACTION statement increments @@TRANCOUNT by 1 and COMMIT statement decrements it by 1.
ROLLBACK statement sets @@TRANCOUNT to 0 (except for cases when transaction is rolled back to savepoint, which does not affect @@TRANCOUNT).
So, if ROLLBACK is issued, all nested transactions are rolled back.
If the value of @@TRANCOUNT is 0, you are not in a transaction.
13. What is a dirty read? How can we allow dirty reads? Give an example when it can be used.
Show/Hide Answer
A dirty read occurs when a transaction reads uncommitted data. Transaction with an isolation level READ UNCOMMITTED allows dirty reads. Also we can allow dirty reads using NOLOCK or READUNCOMMITTED table hints. Suppose one transaction inserts a huge amount of data into the TestTable table in one transaction which takes a lot of time and we need to periodically check how many rows have been inserted at that point of time. We can open another query and
run the following statement SELECT COUNT(*) FROM TestTable WITH (NOLOCK),
which returns TestTable’s rows count by the time it runs. Without allowing
dirty reads, the transaction which retrieves rows count, waits for the transaction inserting
data to complete and then returns the rows’ final count.
https://msdn.microsoft.com/en-us/library/ms709374(v=vs.85).aspx
https://www.mssqltips.com/sqlservertip/4468/compare-sql-server-nolock-and-readpast-table-hints/
14. What is the difference between CHAR and VARCHAR data type?
Show/Hide Answer
CHAR is a fixed-length data type. For CHAR(n) the storage size is n bytes.
VARCHAR is a Variable-length data type. For VARCHAR data type the storage size is the actual length of the data entered + 2 bytes. It is recommended to use CHAR when the sizes of the column data entries are consistent. VHARCHAR is recommended when the column data entries have variable sizes.
15. What is the difference between CHAR and NCHAR data types and what is the difference between VARCHAR and NVARCHAR data types?
Show/Hide Answer
CHAR is a fixed-length non-Unicode string type. For CHAR(n) the storage size is n bytes.
n defines the string length and must be a value from 1 through 8000.
NCHAR a is fixed-length Unicode string type. For NCHAR(n) the storage size is 2*n bytes (however
depending on the string, the storage size of n bytes can be less than the value specified for n).
n defines the string length and must be a value from 1 through 4000.
VARCHAR is a variable-length non-Unicode string type. For VARCHAR data type the storage size is the actual length of
the data entered + 2 bytes.n defines the string length and must be a value from 1 through 8000.
NVARCHAR is a variable-length Unicode string type. For NVARCHAR data type the storage size is two times the actual length of data entered + 2 bytes. n defines the string length and must be a value from 1 through 4000.
16. What is a user-defined function? What are its advantages and limitations? How can it be used ?
Show/Hide Answer
SQL Server user-defined functions are routines that accept parameters, perform some actions and return a result. The latest (latter) can either be a single scalar value or a result set.
Advantages: allowing modular programming and reuse of code,
faster execution,
reducing network traffic
Limitations: cannot modify the database state,
cannot contain an OUTPUT INTO clause that has a table as its target,
can not return multiple result sets,
does not support TRY…CATCH, @ERROR, RAISERROR,
cannot call a stored procedure (however they can call an extended stored procedure),
using SET statements, dynamic SQL or temp tables and FOR XML clause are not allowed,
their nesting level limit is 32,
some Service Broker statements cannot be included in their definition
Usage: can be called in Transact-SQL statements (SELECT, in IF-s condition and so on),
in applications which directly call the function,
in the definition of another user-defined function,
inside a view,
to define a column in a table,
to define a CHECK constraint on a column,
inline functions can be used as a filter predicate for a security policy.
https://msdn.microsoft.com/en-us/library/ms191007.aspx
https://msdn.microsoft.com/en-us/library/ms191320.aspx
https://msdn.microsoft.com/en-us/library/ms186755.aspx
17. What is a T-SQL stored procedure? What are its advantages?
Show/Hide Answer
T-SQL stored procedures are routines written in T-SQL code and stored in a database.
The code in stored procedure can include DML as well as DDL statements, transactions,
TRY..CATCH and so on. They can accept values by input parameters and return results
by output parameters as well as they can return an integer value – return code to
indicate the execution status of a procedure. Also procedures can return one or
more result sets.
Advantages: Reducing network traffic,
enhancing security,
allowing to reuse code,
facilitating code maintenance and encapsulating it,
improving performance
There are also other types of stored procedures- CLR, extended.
18. What is a trigger? What types of triggers do you know?
Show/Hide Answer
A trigger is a special kind of stored procedure that is automatically executed when an specific event takes place. There are three types of triggers-DML trigger, DDL trigger and Logon trigger. DML trigger is executed as the associated DML event occurs, DDL trigger – when the associated DDL statement occur and Logon trigger fires when logon event occurs.
Unlike stored procedures, triggers cannot be executed manually.
DML trigger can be an AFTER trigger which means that trigger is executed after DML statement or it can be an INSTEAD OF trigger meaning that DML trigger is executed instead of DML statement.
Triggers can be used for enforcing database integrity, for auditing and so on.
https://msdn.microsoft.com/en-us/library/ms189799.aspx
19. What are the database recovery models? Describe each of them.
Show/Hide Answer
A recovery model is a database property that defines how transactions are logged,
the requirements for transaction log backup and possible restore operations.
The recovery models are the following:
Simple – Automatically cleans log space to optimize log space usage
No log backups are possible
It is not possible to recover changes after last Full backup
Bulk logged – Uses minimal logging for most bulk operations in this way
optimizing performance for bulk copy operations
Log backups are required
It is possible to recover to the end of any backup,
but point-in-time recovery is not supported.
Full – Log backups are required.
It is possible to do point-in-time recovery (in case if all backups are complete up to that point in time).
20. Suppose we have been provided with the latest full database backup, the latest differential backup (taken after the provided full backup) and all two transaction log backups (taken
after this differential backup and there are no other backups taken after the differential backup).
Which is the correct sequence to restore the database in another environment using the provided files in a way that restored database contains all information included in these backup files?
Show/Hide Answer
Firstly, we need to restore full backup WITH NORECOVERY, then differential backup also WITH
NORECOVERY, after that restore the first log backup again WITH NORECOVERY and finally, restore
the second-latest transaction log backup WITH RECOVERY.
MS SQL Server Database Administrator Interview Questions And Answers
1. How many SQL Server database engine instances can be installed on one computer (stand-alone server)? How many default instances can be installed on the same computer?
Is it possible to install a named instance without having a default instance?
Show/Hide Answer
It is possible to have 50 instances per computer *.
We can have only one default instance on the computer and it is not
necessary to have a default instance to be able to install named instances.
*-For SQL Server 2008, 2008 R2, 2012, 2014, 2016 50 instances per computer for all editions,
for SQL Server 2005 – 50 instances for Enterprise and Developer editions, and 16 for Standard, Workgroup and Express Editions)
https://msdn.microsoft.com/en-us/library/ms143432(v=sql.130).aspx
https://technet.microsoft.com/en-us/library/ms143432(SQL.100).aspx
https://technet.microsoft.com/en-us/library/ms143531(v=sql.90).aspx
2. What are SQL Server authentication modes? Which authentication mode is considered to be more secure and why?
Show/Hide Answer
There are two authentication modes in SQL Server – Windows and mixed authentication modes.
Windows authentication mode – default, integrated with Windows
Mixed authentication mode – authentication is possible both by Windows and by SQL Server.
Windows authentication mode is more secure and Microsoft recommends to use this mode wherever possible.
SQL Server authentication mode is less secure because when SQL Server logins are used, login names and passwords are passed across the network, which is vulnerable. Also Windows has additional password policies which enhance security.
https://msdn.microsoft.com/en-us/library/bb669066(v=vs.110).aspx
3. What are the SQL Server system databases? Describe each of them.
Show/Hide Answer
master, model, msdb, tempdb and resource databases
https://msdn.microsoft.com/en-us/library/ms178028.aspx
4. What are the two types of data files in SQL Server? What is the minimal unit of data that SQL Server writes or reads? What is its size?
Show/Hide Answer
SQL Server databases have two types of data files – Primary and Secondary.
Each database has one primary data file (recommended, but not necessarily having the extension .mdf).
Secondary data files are optional (recommended, but not necessarily having the extension .ndf).
Each data file is logically divided into pages, that are the minimum data for disk I/O operations.
SQL Server reads or writes the whole data pages. The page size is fixed – 8KB.
5. Is it possible to have more than one log file for one database?
If yes, can we increase performance by configuring SQL Server to use them in parallel?
Show/Hide Answer
Yes SQL Server database can have more than one log file, but it is not possible to
use them in parallel. SQL Server uses only one log file until it’s full. So, there cannot
be performance gain. Usually the additional log files are not needed, however in
some cases they can be needed, for example for troubleshooting the database when the first log file
becomes full.
https://www.mssqltips.com/sqlservertip/4083/remove-unnecessary-sql-server-transaction-log-files/
6. What is a CHECKPOINT? Give an examples when CHECKPOINT occurs.
Show/Hide Answer
A CHECKPOINT writes dirty pages (modified pages in memory) and transaction log data from memory
to physical files (data and log files correspondingly) and also records information about the transaction log.
There are four types of CHECKPOINTS: automatic, indirect, manual, and internal.
CHECKPOINTS occur depending on different factors.
For example automatic checkpoints occur depending on recovery interval of server configuration option.
Causes for internal checkpoint can be a database backup, adding or removing database files using ALTER DATABASE statement, stopping the SQL Server service, etc. .
https://msdn.microsoft.com/en-us/library/ms189573.aspx
7. What is a deadlock? How can it be monitored?
Show/Hide Answer
A deadlock occurs when two or more transactions are trying to lock resource on which other transaction(s) have already placed locks and any of these transactions waits for others to release locks to be able to lock a resource. In this way transactions permanently block each other. The SQL Server Database Engine automatically detects deadlocks and terminates one of these transactions with an error to break the deadlock. Deadlocks can be monitored by enabling 1204 or 1222 trace flags and using captured information in SQl Server error log.
Also deadlocks can be monitored by using deadlock graph event in SQL Server Profiler.
https://technet.microsoft.com/en-us/library/ms178104(v=sql.105).aspx
8. Suppose we have the following backups from TestDB database which have been
taken today (no other backups have been taken between these backups):
TestDB_Full1.bak – Full backup taken at 1:00AM
TestDB_Log1.trn – Transaction log backup taken at 1:15AM
TestDB_Diff1.bak – Differential backup taken at 1:25AM
TestDB_Log2.trn – Transaction log backup taken at 1:30AM
We need to restore database by the time the latest log backup have been
taken – 1:30AM. However, we found that TestDB_Diff1.bak had been damaged.
Is it possible to restore TestDB database using only TestDB_Full1.bak,TestDB_Log1.trn
and TestDB_Log2.trn by 1:30AM?
Also, if we had TestDB_Full2.bak full backup taken between TestDB_Log1.trn and TestDB_Diff1.bak backups and in case both – TestDB_Full2.bak and TestDB_Diff1.bak backups were damaged,
would it be possible to restore TestDB database using only TestDB_Full1.bak,TestDB_Log1.trn
and TestDB_Log2.trn by 1:30AM?
TestDB_Full1.bak – Full backup taken at 1:00AM
TestDB_Log1.trn – Transaction log backup taken at 1:15AM
TestDB_Full2.bak – Full backup taken at 1:20AM
TestDB_Diff1.bak – Differential backup taken at 1:25AM
TestDB_Log2.trn – Transaction log backup taken at 1:30AM
Show/Hide Answer
Yes, it is possible for both cases.
https://www.mssqltips.com/sqlservertip/4110/solve-common-sql-server-restore-issues/
9. Suppose we set up TestDB database in a new environment and take its full backup – TestDB_Full1.bak and (no other backups are taken after this full backup). Now database is used intensively
and any data loss will be critical. So, before designing backup strategy we have to immedeately start
taking a full backup. However full backup takes too long time, so in case of disk failure
we will loss all changes (after TestDB_Full1.bak). What can be done in this case to minimize data lose?
Show/Hide Answer
We can start transaction log backups, while full backup is running and in case of failure
we can use TestDB_Full1.bak backup and transaction log backups to restore the database.
https://www.mssqltips.com/sqlservertip/4118/sql-server-backups-and-transaction-log-questions/
10. Suppose we have the following backups from TestDB database which have been
taken today (no other backups have been taken between these backups):
TestDB_Full.bak – Full backup taken at 1:00AM
TestDB_Log1.trn – Transaction log backup taken at 1:15AM
TestDB_CopyOnly.bak – Copy-Only full backup taken at 1:20AM
TestDB_Log2.trn – Transaction log backup taken at 1:30AM
TestDB_Diff.bak – Differential backup taken at 1:35AM
TestDB_Log3.trn – Transaction log backup taken at 1:45AM
Is it possible to restore the database using TestDB_CopyOnly.bak, TestDB_Diff.bak
and TestDB_Log3.trn backups by 1:45AM ?
Is it possible to restore the database using TestDB_CopyOnly.bak, TestDB_Log2.trn
and TestDB_Log3.trn backups by 1:45AM ?
Show/Hide Answer
It is not possible to use differential backups with a COPY_ONLY Full backup for restoring,
so the answer for the first question is NO.
However we can use transaction log backups taken after COPY_ONLY Full backup
with the latter for restoring the database, so the answer for the second question is – YES.
https://www.mssqltips.com/sqlservertip/4110/solve-common-sql-server-restore-issues/
11. Does full backup truncate log file? Does transaction log backup truncate log file,
if yes, can we make sure, that immediately after log backup, log file will be truncated?
Show/Hide Answer
No, full backup does not truncate log file. Transaction log backup truncates log file,
however there are some exceptions when truncation does not occur immediately after log backup.
https://technet.microsoft.com/en-us/library/ms189085(v=sql.105).aspx
https://www.mssqltips.com/sqlservertip/4118/sql-server-backups-and-transaction-log-questions/
12. Suppose we have TestDB database which acts as a principal database in mirroring on high safety with automatic failover mode.
After TestDB_log1.trn backup completes on principal server, the latter goes down and the mirror server becomes principal. While the second (mirror) server acts as a principal, the TestDB_log2.trn backup is taken from TestDB database on that server.
Afterwords the first server becomes online and we manually make it principal, and TestDB_log3.trn backup is taken on that server.
Is it possible to restore TestDB database using its full backup (taken on the first-principal server just before TestDB_log1.trn backup), TestDB_log1.trn, TestDB_log2.trn and TestDB_log3.trn backups?
Show/Hide Answer
Yes, it is possible.
13. What are the differences between rebuilding and reorganizing indexes?
Show/Hide Answer
Both are aimed to fix index fragmentation.
In case of rebuilding, index is dropped and re-created, also the new value for fill factor can be set.
We can rebuild index either online or offline.
Reorganizing does not drop and recreate an index. Its defragments the leaf level of
index and compacts the index pages according to the existing fill factor value (this value cannot be
changed in case of reorganizing, moreover other index options also cannot be specified). Reorganizing uses minimal resources and can be executed only online.
14. What is index’s fill-factor option ? When is it set? How is it related to performance of SELECT and INSERT/UPDATE statements?
Give an example when setting nonzero fill-factor value does not achieve write performance gain?
Show/Hide Answer
The fill-factor value defines the percentage of space on each leaf-level page to be filled with data
at the time of index creation or rebuilding. Remaining free space is for future usage.
As mentioned before, fill-factor value is being set when index is created or rebuilt. So, after index
creation or rebuilding the free space will be decreased depending on the index expansion.
Fill-factor allows to reduce page splits by reserving free space for index growth. Due to correctly
chosen fill-factor value INSERT statements on underlying table became faster. The UPDATE statements, that cause the size of the rows to grow, also become faster. However setting the value of fill-factor different than 100(0) affects the performance of SELECT statements. In addition, the index with nonzero fill-factor value, requires more storage space.
When all new data is added to the end of the table, the nonzero fill-factor value does not increase write performance, because the empty space in the index pages will not be filled. The typical example of that is an index on IDENTITY column. In this case the inserted key values are always increasing, so index rows are logically added to the end of the index.
https://msdn.microsoft.com/en-us/library/ms177459(v=sql.105).aspx
15. How can we automate SQL Server administrative tasks such as backup, index maintenance and so on?
Show/Hide Answer
We can do it by creating SQL Server Agent jobs. It is also possible to create maintenance plans which are also created corresponding SQL Server Agent jobs.
However maintenance tasks have the same limitations and in some cases they are not that flexible (for example we cannot check index fragmentation level before rebuilding or reorganizing it,
mirrored backups are also not supported and so on) than the manually written code.
https://docs.microsoft.com/en-us/sql/ssms/agent/sql-server-agent
https://msdn.microsoft.com/en-us/library/ms187658.aspx
https://msdn.microsoft.com/en-us/library/ms187658.aspx
16. Is it possible to combine database mirroring and log shipping?
If yes, is it possible to continue log shipping in case failover occurs?
Show/Hide Answer
Yes, the principal database in a mirroring session can also serve as the primary database in a log shipping, or vice versa.
It it also possible to continue log shipping after failover by configuring mirror server as a primary server for log shipping with the same configuration as the principal database.
17. What are the types of SQL Server replication? What are the transactional replication agents? Describe each of them.
Show/Hide Answer
Transactional replication, Merge replication, Snapshot replication.
Transactional replication is implemented by the following SQL Server agents: Snapshot Agent, Log Reader Agent, and Distribution Agent.
https://msdn.microsoft.com/en-us/library/ms151176.aspx
https://msdn.microsoft.com/en-us/library/ms151176.aspx#HowWorks
18. What is the Always On Failover Cluster Instances in SQL Server 2016 ?
From which failures does it protect and from which it does not protect ?
Show/Hide Answer
A Failover Cluster Instance (FCI) is a single instance of SQL Server installed across Windows Server Failover Clustering (WSFC) nodes and, possibly, across multiple subnets. FCI consists of a set of physical servers (nodes) with the same hardware and software configuration.
On the network, an FCI appears to be an instance of SQL Server running on a single computer. In case when the current node becomes unavailable FCI provides failover from one WSFC node to another.
Failover Cluster Instance (FCI) consists of a set of physical servers (nodes) that contain similar hardware configuration as well as identical software configuration that includes operating
system version and patch level, and SQL Server version, patch level, components, and instance name.
Identical software configuration is necessary to ensure that the FCI can be fully functional as it fails over between the nodes.
FCI protects from hardware failures, operating system failures, application or service failures.
Shared storage failure is not protected by FCI (shared storage can be the single point of failure).
19. Is it possible to limit memory usage by SQL Server ?
Show/Hide Answer
Yes, it is.
https://www.mssqltips.com/sqlservertip/4182/setting-a-fixed-amount-of-memory-for-sql-server/
20. Is it possible to access data from SQL Server instance from outside of SQL Server?
Show/Hide Answer
21. We execute a large SQL script in SQL Server Management Studio and receive an error “Cannot execute script. Insufficient memory to continue the execution of the program. (mscorlib)” . What is the problem and how can we solve it?
Show/Hide Answer
22. Tell some system stored procedures which can be used for performing monitoring tasks (get an information about current SQL Server users and processes, information about locks, disk space usage by a table, CPU usage, I/O usage and so on).
Show/Hide Answer
sp_who, sp_lock, sp_spaceused, sp_monitor
MS SQL Server Database Developer Interview Questions And Answers
1. Is there a difference between decimal and numeric data types?
Show/Hide Answer
There is no difference, they are absolutely the same.
Both are fixed precision and scale numbers. For both, the minimum precision is 1 and
the maximum is 38 (18 – by default). Both data types cover the range from -10^38+1 to 10^38-1.
Only their names are different and nothing more.
2. What is a ROWVERSION data type? Where can it be used? Is there a difference between ROWVERSION and TIMESTAMP data types?
Show/Hide Answer
3. Is there a difference between a unique index and unique constraint?
Show/Hide Answer
4. What are the differences between the local temporary tables and global temporary tables?
Show/Hide Answer
https://technet.microsoft.com/en-us/library/ms186986(v=sql.105).aspx
https://technet.microsoft.com/en-us/library/ms177399(v=sql.105).aspx
https://www.mssqltips.com/sqlservertip/4031/sql-server-global-temporary-table-visibility/
5. What is a table variable? Where can it be used? Is it possible to create indexes on the table variables?
Are they affected by a rollback in transaction.
Show/Hide Answer
6. What is a Common Table Expression (CTE) ?
Show/Hide Answer
7. Where are local and global temporary tables, table variables and CTEs stored?
Show/Hide Answer
Local and global temporary tables as well as table variables are stored in tempdb database.
However, CTEs are not stored as an object, they exist only for the duration of the query,
in other words they are stored in memory (RAM).
https://technet.microsoft.com/en-us/library/ms186986(v=sql.105).aspx
https://technet.microsoft.com/en-us/library/ms177399(v=sql.105).aspx
https://technet.microsoft.com/en-us/library/ms190766(v=sql.105).aspx
8. Is it possible to update data in base table using view?
Show/Hide Answer
Yes, it is, but there are some limitations:
9. What is the difference between READPAST and NOLOCK table hints?
Show/Hide Answer
10. What is the difference between Repeatable Read and Serializable Transaction Isolation Levels?
Show/Hide Answer
11. What is the difference between Serializable and Snapshot Transaction Isolation Levels?
Show/Hide Answer
12. Is it possible to include DDL statements in one transaction in Microsoft SQL Server?
When TRUNCATE TABLE statement is included in transaction and this transaction is rolled back,
is the truncated data rolled back?
Show/Hide Answer
Yes, it is possible with some exceptions.
Yes, TRUNCATE is a DDL command which can be included in transaction and truncated data will be rolled back in case of ROLLBACK.
13. Suppose we have a column which allows NULLs. We need to enforce uniqueness of values in this column which are not NULL.
How can we implement this solution?
Show/Hide Answer
As we know UNIQUE index allows only one NULL in a column, so we cannot create UNIQUE index in this case.
We can create UNIQUE FILTERED index instead:
CREATE UNIQUE NONCLUSTERED INDEX <index_name>
ON <table name>(<column_name>)
WHERE <column_name> IS NOT NULL
GO
https://msdn.microsoft.com/en-us/library/cc280372.aspx
14. What is an index with included columns ? How can it improve query performance ?
Show/Hide Answer
It is possible to create non-clustered index which besides key columns also includes non key columns (usually all columns in the query).
In this case query optimizer can locate all the column values within the index, therefore table or clustered index data is not accessed that improves query performance.
https://msdn.microsoft.com/en-us/library/ms190806(v=sql.105).aspx
15. Is it possible to use more than one TRY…CATCH block in the stored procedure?
Give error examples which are unaffected by a TRY…CATCH.
Show/Hide Answer
Yes it is possible.
Object name resolution errors, syntax errors that prevent a batch from running, warnings or informational messages with severity of 10 or lower and so on.
16. Suppose you have a stored procedure which has a one TRY…CATCH block. There is a transaction
which is opened in TRY block and in case of success committed in this block.
The ROLLBACK statement is included in the CATCH block. However when procedure runs in a new
environment we receive the following error “Transaction count after EXECUTE indicates a mismatching number of BEGIN and COMMIT statements”. We investigate and find out that some tables that are used in transaction are missing in new environment. How to correct the code in stored procedure to avoid this error and ROLLBACK successfully in the above mentioned situations?
Show/Hide Answer
We need to set set XACT_ABORT to ON in our procedure.
17. Is it possible to call stored procedure inside user defined function ? Is it possible to call user-defined function inside user-defined function?
Show/Hide Answer
No, it is not possible to call stored procedure inside user-defined function.
Yes, user-defined functions can be nested up to 32 levels.
18. One of the stored procedures in our database gives an error when it is called from application with specific values of parameters.
How can you catch that procedure’s call and investigate the problem ?
Show/Hide Answer
You can use SQL Server Profiler to catch procedure’s call and debug it in SQL Server Management Studio.
https://msdn.microsoft.com/en-us/library/ms181091.aspx
https://msdn.microsoft.com/en-us/library/hh272701(v=vs.103).aspx
19. What is an execution plan? What is the difference between Actual Execution Plan and Estimated Execution Plan?
What is the difference between Index Seek and Index Scan ?
Show/Hide Answer
https://technet.microsoft.com/en-us/library/ms178071(v=sql.105).aspx
https://blogs.msdn.microsoft.com/craigfr/2006/06/26/scans-vs-seeks/
https://technet.microsoft.com/en-us/library/ms190400(v=sql.105).aspx
https://technet.microsoft.com/en-us/library/ms190400(v=sql.105).aspx
20. How can we execute Dynamic SQL statements ? Why is sp_executesql stored procedure considered more secure than using EXEC statement?
Show/Hide Answer
We can do it either by sp_executesql stored procedure or EXEC statement.
sp_executesql stored procedure considered more secure because we can enhance security by using parametrization.
https://technet.microsoft.com/en-us/library/ms161953(v=sql.105).aspx
https://technet.microsoft.com/en-us/library/ms175170(v=sql.105).aspx
https://docs.microsoft.com/en-us/sql/odbc/reference/dynamic-sql